tl;dr - Was sind Embeddings?
Embedding für KI und Machine Learning ist die Schlüsseltechnologie, um komplexe Daten wie Texte, Bilder und Graphen in numerische Vektoren zu verwandeln. Dadurch können künstliche Intelligenz und Machine-Learning-Modelle Beziehungen, Bedeutungen und Muster effizient erkennen, vergleichen und nutzen. In diesem Guide erfährst du, wie Embeddings funktionieren, welche Arten es gibt, wie sie im KI-Alltag eingesetzt werden und wie du sie selbst in deinen Projekten verwendest – von NLP über Empfehlungssysteme bis zu Bildanalysen und modernen Suchmaschinen.
1. Was sind Embeddings? – Grundlagen und Bedeutung
In der rasant fortschreitenden Welt der künstlichen Intelligenz (KI) und des Machine Learning (ML) taucht ein Begriff immer wieder auf: Embedding. Oft im Hintergrund agierend, bilden Embeddings die unsichtbare Brücke zwischen der reichen, chaotischen Realität aus Text, Bildern und anderen Datenquellen – und der maschinellen Verarbeitung, die daraus nutzbares Wissen destilliert. Dieser Blogartikel ist anders als die üblichen, oft trockenen Definitionen: Wir nehmen dich mit auf eine Reise von den allerersten Grundlagen, über faszinierende Deep Dives bis hin zu praxisrelevanten Tipps und Code-Beispielen. Du erfährst, wie Embeddings funktionieren, welche revolutionären Möglichkeiten sie eröffnen – und wie du sie selbst gezielt einsetzt, um aus deinen Daten echten Mehrwert zu ziehen.
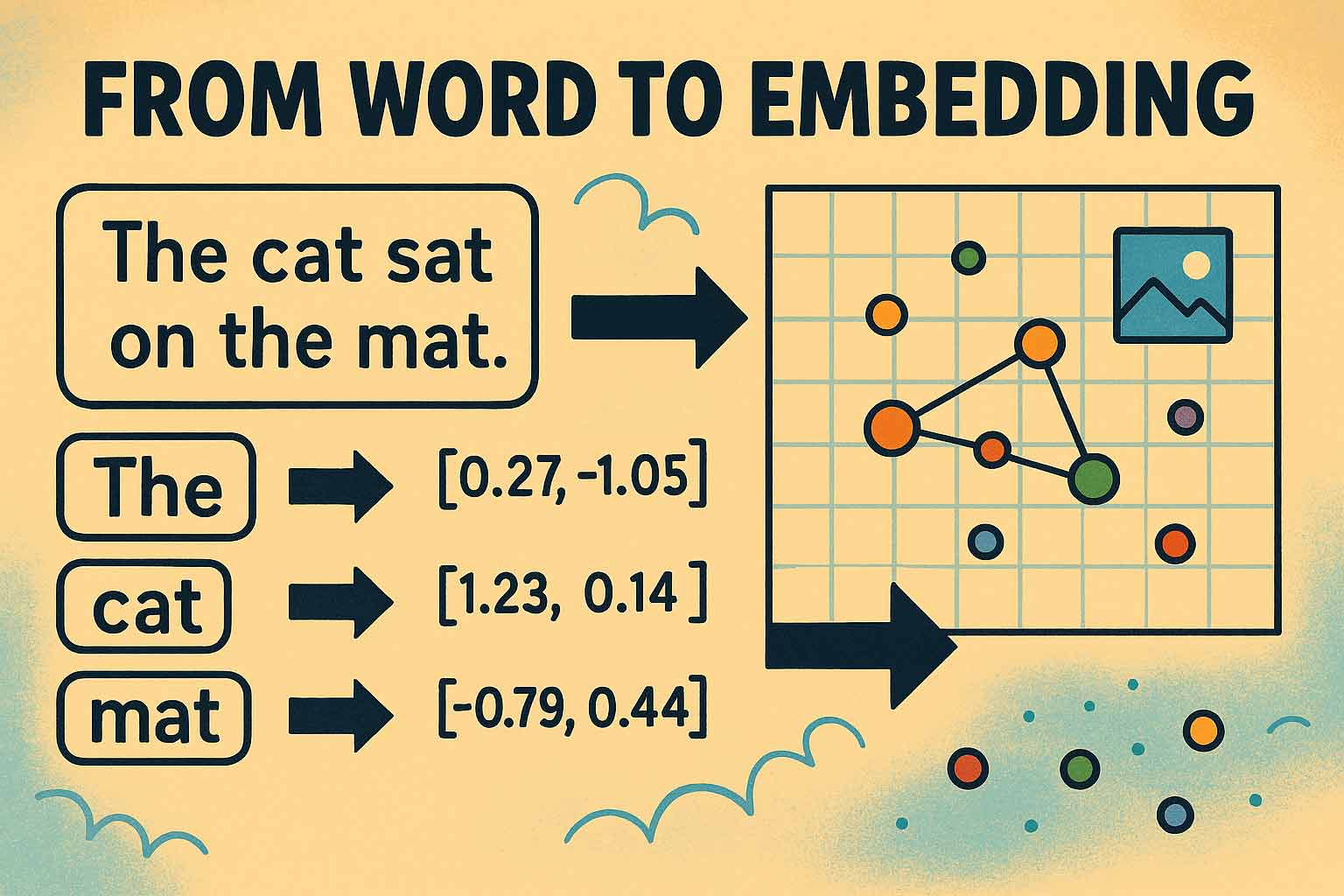
1.1 Definition: Was versteht man unter Embeddings?
Stell dir vor, du könntest die Bedeutung von Worten, Bildern oder gar Musik in eine präzise mathematische Form übersetzen – sodass Computer auf einen Blick Zusammenhänge, Ähnlichkeiten und Unterschiede erkennen können. Genau das leisten Embeddings: Sie verwandeln komplexe Objekte wie Wörter, Sätze, Dokumente, Bilder oder sogar Netzwerkstrukturen in sogenannte Vektoren – Listen aus Zahlen verschiedener Länge, die sich im sogenannten Vektorraum anordnen lassen.
Diese Vektordarstellungen machen es Maschinen möglich, die semantische Nähe zwischen Objekten zu „verstehen“. Zwei ähnlich gemeinte Texte erhalten z.B. ähnliche Zahlenfolgen – ihre Punkte im Raum liegen nah beieinander. Daraus ergeben sich beeindruckende Anwendungen: Von der blitzschnellen Suche nach ähnlichen Dokumenten über personalisierte Empfehlungen bis hin zu intelligenter Betrugserkennung in Finanzdaten.
1.2 Warum sind Embeddings essenziell für KI?
Der menschliche Geist erkennt intuitiv Ähnlichkeiten und Beziehungen – sei es zwischen Begriffen, Bildern oder abstrakten Konzepten. Computer aber benötigen numerische Darstellungen, um Muster zu erkennen. Ohne Embeddings müssten Maschinen sämtliche möglichen Varianten und Kombinationen explizit vergleichen – ein unlösbares Problem bei der schieren Masse an Daten.
Embeddings komprimieren relevante Inhalte auf intelligente Weise, bewahren dabei aber die wichtigsten Informationen: Bedeutung, Kontext, Beziehungen. Sie sind damit das Rückgrat moderner KI-Anwendungen wie Suchmaschinen, Empfehlungssystemen, Chatbots und Sprachmodellen wie GPT oder BERT.
1.3 Historische Entwicklung & Überblick
Die Idee, Inhalte als Vektoren numerisch zu kodieren, existiert schon seit den Anfängen des Information Retrieval. In den letzten zehn Jahren hat sich die Technik jedoch rasant entwickelt: Von simplen One-Hot-Encodings über statische Wörterbücher wie Word2Vec hin zu komplexen, Kontext-abhängigen Modellen – allen voran BERT und die modernen Transformer-Ansätze.
- Frühe Ansätze: Einfache Beziehungsmodelle, z.B. Bag-of-Words-Vektoren.
- Statische Embeddings: Word2Vec, GloVe – erstmals semantische Nähe im Zahlenraum.
- Kontextuelle Embeddings: BERT & Co. können gleiche Wörter in unterschiedlichen Kontexten unterschiedlich übersetzen.
Heute gehören Embeddings zu den Schlüsseltechnologien jeder fortschrittlichen KI – sei es in Text, Bild, Audio oder komplex vernetzten Daten.
2. Von Rohdaten zum Vektorraum: Wie entstehen Embeddings?
2.1 Die Rolle der Tokenisierung
2.1.1 Was ist Tokenisierung – und wie unterscheidet sie sich von Embeddings?
Bevor ein KI-System überhaupt Embeddings erzeugen kann, müssen die rohen Daten aufbereitet werden. Besonders bei Textdaten kommt hier die sogenannte Tokenisierung zum Einsatz: Sie zerlegt Fließtext in kleinere Einheiten – sogenannte Tokens. Diese können Wörter, Silben (Subwords) oder Zeichen sein.
Die Aufgabe der Tokenisierung ist es, einen Text so in Einzelteile zu zerlegen, dass der Rechner damit weiterarbeiten kann – sie verwandelt Sprache also in eine Sequenz von Symbolen oder IDs. Erst mit diesen IDs kann ein nachgelagertes Embedding-Modell arbeiten und zu jedem Token eine Zahlenliste (Vektor) erzeugen.
2.1.2 Beispiele: Tokenisierung vs. Embedding
- Tokenisierung: „I love machine learning“ → [„I“, „love“, „machine“, „learning“] → [101, 2293, 724, 1331]
- Embedding: Die Zahlen („Token IDs“) werden in feste Vektoren übersetzt: [0.12, -0.54, ...]
- Entscheidender Unterschied: Die Tokenisierung ordnet und kodiert – Embeddings füllen mit Bedeutung und Kontext auf!
2.2 Vom Token zum Vektor: Der Embedding-Prozess
2.2.1 Numerische Darstellung von Objekten (Low-Dimensional/Dense Vectors)
Nach der Tokenisierung werden die einzelnen Tokens vom Embedding-Modell in numerische Vektoren übersetzt. Stell dir diesen Prozess vor wie eine Landkarte: Jedes Objekt (z.B. ein Wort) bekommt Koordinaten in einem oft hunderte bis tausende Dimensionen umfassenden Raum. Die Lage der Punkte im Raum reflektiert semantische Ähnlichkeiten – „Auto“, „Fahrzeug“ und „LKW“ werden eng gruppiert, „Pizza“ und „Buch“ liegen weiter entfernt.
Durch diese Transformation wird die ursprüngliche, hohe Komplexität der Daten gezähmt und für den Algorithmus verständlich gemacht. Anstatt mit millionenfachen Einzel-Kombinationen umzugehen, genügt nun ein Blick auf die Position und Entfernung von Punkten im Vektorraum, um Beziehungen automatisch festzustellen.
2.2.2 Dimensionen und ihre Bedeutung
Die sogenannte Dimensionalität eines Embeddings bestimmt, wie viele Eigenschaften gleichzeitig abgebildet werden können. In der Praxis reichen zwei bis drei Dimensionen für einfache Beispiele (z.B. Ort auf der Landkarte), während Wort-Embeddings oder Bild-Features Vektoren mit meist 256, 512, 768 oder gar 2048 Dimensionen umfassen.
Das Faszinierende ist: Umso mehr Dimensionen, desto differenzierter lassen sich komplexe Beziehungen speichern – auch wenn die meisten Dimensionen für das menschliche Auge nicht mehr intuitiv fassbar sind.
2.3 Architektur moderner Embedding-Modelle
2.3.1 Neuronale Netze: Embedding Layer, Trainingsprozess & Backpropagation
Moderne Embeddings werden meist mittels tiefer neuronaler Netze („Deep Learning“) erlernt: Im Kern enthalten viele Netzwerke eine eigene Embedding-Layer, die die Token-IDs in Vektoren abbildet. Während des Trainings lernen diese Schichten, relevante Bedeutungsdimensionen automatisch zu verfeinern.
- Der Trainingsprozess läuft meist überwacht ab (z.B. bei Vorhersageaufgaben) oder selbstüberwacht, wie beim Masked-Language-Modeling.
- Backpropagation-Verfahren optimieren stetig Embedding-Vektoren: Ähnliche Objekte rücken durch Trainingsrückmeldungen näher zusammen.
Die so entstandenen Embedding-Vektoren werden nach Training im Modell gespeichert und stehen für Abfragen oder weitere Aufgaben bereit.
2.3.2 Lossy Compression: Chancen und Limitationen
Ein zentrales Prinzip bei Embeddings ist die verlustbehaftete Kompression („lossy compression“): Um komplexe Daten in niedrige Vektor-Dimensionen zu pressen, wird zwangsläufig ein Teil der Informationen weggelassen. Ziel ist es jedoch, gerade die für die Zielaufgabe wichtigsten semantischen Merkmale zu erhalten.
- Beispiel Text: Verschiedene Bedeutungsnuancen oder Assoziationen könnten zusammengefasst und so vereinfacht werden. Das macht Modelle oft robuster, kann aber zu Kontextverlust führen.
- Beispiel Bild: Detailinformationen wie feine Farbabstufungen gehen möglicherweise verloren, Hauptobjekte und ihre Anordnung bleiben erhalten.
3. Arten von Embeddings und ihre Technologien
3.1 Statische Embeddings: Word2Vec, GloVe & Co.
3.1.1 Funktionsweise & Vorteile
Die ersten großen Durchbrüche bei Embeddings kamen mit den statischen Verfahren: Word2Vec (Google), GloVe (Stanford) oder FastText (Facebook) übersetzen jedes Wort zu einem festen Vektor – unabhängig vom Kontext, in dem es steht.
Das Training erfolgt auf riesigen Textkorpora. Die Modelle lernen, Wörter mit ähnlichen Kontexten auch im Vektorraum zusammenzubringen: „König – Mann + Frau = Königin“ ist ein klassisches Beispiel dafür, wie sich sogar Analogie-Operationen direkt auf den Embeddings ausführen lassen.
3.1.2 Grenzen statischer Embeddings (Polysemie etc.)
Der Nachteil: Ein Wort wie „Bank“ erhält immer denselben Vektor, egal ob von einer Geldbank oder eine Parkbank die Rede ist. Sprachliche Vieldeutigkeiten (Polysemie) und Kontextänderungen werden hier noch nicht abgebildet.
3.2 Kontextuelle Embeddings: BERT & Transformer-basierte Ansätze
3.2.1 Kontextabhängigkeit und Semantic Similarity
Mit der Einführung von BERT (Google) und verwandten Transformer-Modellen wurde ein Paradigmenwechsel eingeleitet: Jedes Wort, jede Phrase, jeder Satz bekommt situativ angepasste Embedding-Vektoren – in Abhängigkeit vom umgebenden Kontext.
Das bedeutet zum Beispiel: Das Wort "Java" bekommt komplett unterschiedliche Vektoren, je nachdem ob vom Programmieren, von der Insel oder von einer Tasse Kaffee die Rede ist. Semantische und syntaktische Unterschiede werden so erstmals maschinell berücksichtigt.
Die Vielschichtigkeit von Sprache und Kontext wird so viel besser übertragen. Auch Satz- und Dokument-Embedding-Modelle (z.B. Universal Sentence Encoder oder SentenceTransformers) liefern sinnvolle Vektoren für ganze Zusammenhänge.
3.3 Spezialisierte Embedding-Verfahren
3.3.1 Bild- und Audioembeddings (CNNs, RNNs, CLIP)
Neben Text werden Embeddings heute auf verschiedenste Datenarten angewendet:
- Bild-Embeddings: Convolutional Neural Networks (CNNs), wie ResNet, extrahieren Bildmerkmale (feature vectors), die z. B. Objektklassen oder Bildähnlichkeit beschreiben. Modelle wie CLIP verknüpfen Bild- und Texteigenschaften in einem gemeinsamen Vektorraum.
- Audio-Embeddings: RNNs und CNNs erfassen akustische Eigenschaften wie Tonhöhe, Rhythmus, Sprecherpräferenzen oder sogar Musikstil als Vektoren.
3.3.2 Graph Embeddings (Node2Vec, GraphSAGE & Anwendungen)
Auch für Daten mit Beziehungen – z.B. soziale Netzwerke, Molekularstrukturen oder Verkehrsnetze – können Embeddings erzeugt werden. Algorithmen wie Node2Vec oder GraphSAGE wandeln Knoten und Kanten in zusammenhängende Vektoren, sodass Bedeutung und Beziehungen im Netzwerk mathematisch eingefangen werden.
Das ist besonders wichtig für Aufgaben wie Link Prediction (wer könnte mit wem in Kontakt treten?), Community Detection, Betrugserkennung oder Empfehlungssysteme.
3.3.3 Multimodale Embeddings: Text, Bild & Audio gemeinsam lernen
Der neueste Stand der Forschung sind multimodale Embeddings, die verschiedene Datenarten ganzheitlich abbilden: Zum Beispiel verknüpft das Modell CLIP Bild und zugehörigen Text in ein gemeinsames Vektorformat. Dadurch wird etwa eine Bildsuche durch beschreibenden Text möglich – oder ein Video kann automatisch mit passender Musik verknüpft werden.
4. Embedding Modelle im Einsatz: Praktische Anwendungsfelder
4.1 Natural Language Processing (NLP) & Suchmaschinen
4.1.1 Semantische Suche & Kontext-gestützte Abfragen
Embeddings sind das Herzstück moderner semantischer Suchmaschinen. Anstatt Suchbegriffe wortwörtlich abzugleichen, werden sowohl die Suchanfrage als auch die Dokumente selbst als Vektoren dargestellt. Der Computer kann so verstehen, dass eine Suchanfrage nach „klimafreundlicher Urlaub in Gebirge“ auch Sätze wie „Nachhaltige Reiseangebote in Alpenregion“ als relevante Treffer listet – selbst von Synonymen oder umformulierten Phrasen.
Das revolutioniert beispielsweise die Arbeit in Researchico, wo Nutzer ihre Dokumentbibliothek mithilfe semantischer Embeddings intelligent durchsuchen und fundierte Auswertungen in natürlicher Sprache erhalten. Diese Form der semantischen Suche hebt herkömmliche Keyword-basierte Methoden auf ein neues Level und wird zunehmend zum Standard im digitalen Wissensmanagement.
4.1.2 Sentimentanalyse, Textklassifikation, Frage-Antwort-Systeme
Auch für die maschinelle Klassifikation von Stimmungen („Positiv/Negativ“), das Thema Routing von Supportanfragen oder in Chatbots sind Embeddings unerlässlich. Durch die Vektorrepräsentation versteht die Maschine Bedeutungsnuancen – und ist in der Lage, thematische Cluster zu bilden, Fragen gezielt zu beantworten oder Texte automatisch zu kategorisieren.
4.2 Computer Vision & Bildretrieval
4.2.1 Objekterkennung, Klassifikation & Ähnlichkeits-Suche
Im Bereich der Bildanalyse ermöglichen Embeddings nicht nur die schnelle und zuverlässige Objekterkennung, sondern auch die Suche nach ähnlichen Bildern (z.B. in E-Commerce, Kunst oder medizinischer Diagnostik). Ein Bild wird in einen Feature-Vektor gewandelt – und dieser mit Millionen anderen verglichen.
4.3 Recommender Systeme & Collaborative Filtering
4.3.1 User- & Item-Embeddings in Empfehlungsalgorithmen
Empfehlungssysteme wie diejenigen von Netflix oder Spotify nutzen Embeddings, um sowohl Nutzer- als auch Produktpräferenzen zu erfassen. Die KI lernt: „Wer Krimis mag, findet wahrscheinlich auch Thriller spannend“, oder: „Kunden, die Produkt X gekauft haben, mögen auch Y“. Embeddings bringen komplexe Nutzerverhalten und Inhaltsmerkmale effizient zusammen – Grundlage für personalisierte Vorschläge.
4.4 Graphbasierte Anwendungen & Netzwerk-Analysen
Ob in Sozialen Netzwerken, Verkehrsplanungen oder bei Molekül- und Strukturanalysen: Graph-Embeddings sind die Schlüsseltechnologie, um Beziehungen und Strukturen mathematisch zu erschließen. Von Fraud-Detection bis Community-Erkennung – Netzwerk-Sichten lassen sich als "Cluster im Vektorraum" analysieren.
4.5 Anomalie- & Betrugserkennung
Beim Vergleich von Transaktionsdaten, Netzwerkverkehr oder Nutzerverhalten helfen Embeddings, „Ausreißer“ im dichten Zahlenraum zu entdecken – und damit Betrug, Hacking-Muster oder ungewöhnliche Vorgänge schneller als je zuvor zu identifizieren.
4.6 Multimodale und Cross-Domain-Anwendungen (z. B. CLIP, MUSE)
Sich verändernde Datenlandschaften und die steigende Integration verschiedenster Quellen erfordern flexible, multimodale Embeddings: Hiermit werden Verbindungen zwischen Text, Bild oder sogar Sprache/Klang geschaffen – zum Beispiel für Barrierefreiheit (Bilderkennung mit Textausgabe), crossmodale Suchmaschinen oder Multilingual-Übersetzungsdienste.
5. Vektorraumanalysen und Ähnlichkeitssuche
5.1 Abstandsmaße und Ähnlichkeitsmetriken (z. B. Kosinus, Euklid)
Sobald Objekte als Vektoren vorliegen, stellt sich die Frage: Wie misst man effektiv deren Ähnlichkeit? Am weitesten verbreitet sind:
- Kosinus-Ähnlichkeit: Misst den Winkel zwischen zwei Vektoren – ideal für Text.
- Euklidische Distanz: Direkter Abstand im n-dimensionalen Raum – häufig bei Bildern.
- Weitere Maße: Manhattan, Jaccard, Hamming und anwendungsbezogene Varianten.
Die Auswahl der Metrik beeinflusst direkt, wie relevant die Resultate einer Suche sind!
5.2 Visualisierung von Embeddings (z. B. t-SNE, PCA, UMAP)
Um hochdimensionale Embedding-Vektoren für den Menschen greifbar zu machen, werden Methoden wie PCA (Hauptkomponentenanalyse), t-SNE oder UMAP genutzt. Sie projizieren die Informationen auf zwei oder drei Dimensionen, damit Cluster und Nähebeziehungen sichtbar werden – beispielsweise als interaktive Plot-Visualisierung.
5.3 Vektordatenbanken: Speicherung und schnelle Suche
5.3.1 Aufbau & Funktionsweise von Vektordatenbanken
Mit der zunehmenden Relevanz von Embeddings wächst auch der Bedarf an spezialisierten Datenbanken, die Vektoren speichern, durchsuchen und effizient abgleichen können: sogenannte Vektordatenbanken. Kernprinzip: Dokumente, Bilder oder Audio werden bei Einfügen automatisiert in Embeddings umgewandelt, mit Metadaten verknüpft und als Suchbasis verwendet.
- Sammlungen (Collections) nehmen beliebige Datentypen auf
- Suchanfragen werden als Embeddings eingebracht und mit dem Datenbestand verglichen
- Sortierung nach Ähnlichkeit („Top-N“) ersetzt die klassische exakte Keyword-Suche
5.3.2 Beispiele & Best Practices
Praktische Anwendungen finden sich in intelligenten Dokumentenarchiven, der Analyse großer wissenschaftlicher Text-Sammlungen oder auch beim schnellen (und datensparsamen!) Bild-Vergleich in KI-gestützten CMS-Systemen.
6. Trainingsprozess und Optimierung von Embeddings
6.1 Überblick: Embedding-Generierung mit neuronalen Netzen
Ein zentrales Element jeder modernen Embedding-Struktur ist die Embedding-Layer im neuronalen Netz. Sie startet meist mit zufälligen Werten, die im Trainingsprozess durch Rückmeldungen (Backpropagation) systematisch angepasst werden.
- Bei Masked Language Modeling (wie in BERT) werden zufällig Wörter aus Sätzen entfernt und vom Modell vorhergesagt – so lernt es die Zusammenhänge statistisch optimal abzubilden.
- Über Millionen bis Milliarden Durchläufe entstehen so dichte, bedeutungsvolle Vektoren für die unterschiedlichsten Anwendungsfälle.
6.2 Trainingsdaten: Bedeutung von Qualität & Vielfalt
Kein Modell ist besser als seine Trainingsdaten – das gilt besonders für Embeddings! Die Vielfalt, aber auch die Qualität (Rechtschreibung, Repräsentativität, Ausgeglichenheit verschiedener Domänen) entscheidet darüber, wie robust und umfassend die erlernten Beziehungen sind. Vortrainierte Modelle lassen sich zudem gezielt nachtrainieren (Fine-Tuning), etwa auf spezielle Branchen-Sprache.
6.3 Feintuning & Transfer Learning: Domänenspezifische Anpassung
Oft ist es sinnvoll, ein großes, vortrainiertes Embedding-Modell auf eine spezifische Aufgabe anzupassen, z.B. Juristendeutsch oder medizinische Fachbegriffe. Das sogenannte Fine-Tuning nutzt wenige, hochwertige Spezialdaten, um den Embedding-Raum punktgenau zu verschieben. Transfer Learning ist dadurch extrem daten- und zeiteffizient.
6.4 Monitoring & Evaluation von Embedding-Qualität
Zur Qualitätskontrolle werden verschiedene Verfahren eingesetzt:
- Vergleich der Kosinus-Ähnlichkeit bekannter Begriffspaare
- Performance auf Downstream-Tasks (z.B. Textklassifikation, Empfehlung)
- Interpretierbarkeit durch Visualisierung (Siehe Kapitel 5.2)
Messgrößen sind u.a. Loss, Accuracy oder Analogie-Testaufgaben.
7. Herausforderungen, Limitationen & Best Practices
7.1 Verlust von Kontextinformationen & Bias
So kraftvoll Embeddings auch sind – sie sind nicht ohne Fallstricke! Jede Komprimierung führt zu Informationsverlust. Bei schlecht ausgewählten Trainingsdaten entstehen zudem oft Biases (z.B. kulturelle oder geschlechtsspezifische Verzerrungen). Auch können kleine Unterschiede bei der Datenqualität große Auswirkungen auf den Embedding-Raum haben.
7.2 Interpretierbarkeit und Black-Box-Problematik
Je komplexer ein Embedding-Modell, desto schwerer fällt die Interpretation seiner Ergebnisse: Was genau bedeutet eine bestimmte Dimension im Vektor? Wie lässt sich verstehen, warum das Modell zwei Wörter ähnlich findet? Forschung und Praxis arbeiten stetig daran, mehr Transparenz („Explainable AI“) in diese Prozesse zu bringen.
7.3 Umgang mit Out-of-Vocabulary und seltenen Begriffen
Ein weiteres Problem: Unbekannte oder seltene Begriffe (OOV terms) können von klassischen Embeddings nicht verarbeitet werden. Moderne Modelle nutzen deshalb Subword-Tokenisierung und Byte Pair Encoding, um selbst bisher ungesehene Wörter aus bekannten Bestandteilen zusammenzusetzen.
7.4 Speicherbedarf & Effizienz bei großen Embedding Spaces
Gerade bei sehr großen Datensätzen können Embedding-Datenbanken enorme Speicher- und Rechenanforderungen erzeugen. Hier helfen Dimension-Reduktion, Speicherkomprimierung (z.B. Quantisierung) und verteilte Infrastrukturen, Vektor-Suche praxistauglich zu machen.
8. Ausblick und Trends – Die Zukunft der Embeddings
8.1 Multimodale & universelle Embeddings
Die Zukunft ist multimodal: Embeddings werden unterschiedlichste Datenquellen sowie verschiedene Sprachen und Kulturen in gemeinsamen Vektorräumen abbilden. Universelle Embeddings werden damit zum Schlüssel für globale, domänenübergreifende KI-Anwendungen.
8.2 Prompt Engineering vs. Fine-Tuning: Wofür ist welches Verfahren geeignet?
Statt immer größere Modelle zu „finetunen“, setzen viele KI-Projekte inzwischen gezielt auf intelligentes Prompt Engineering: Durch genaue Aufgabenstellungen und Kontextangaben im Input kann auch ein grundsätzliches Sprachmodell für spezifische Antworten gesteuert werden. Fine-Tuning bleibt für stark domänenspezifische Aufgaben weiter unersetzlich, beides ergänzt sich ideal.
8.3 Integration in moderne KI-Workflows und SaaS-Lösungen (z. B. Researchico)
Neue SaaS-Plattformen wie Researchico zeigen, wie einfach sich leistungsfähige Embedding-Technologie auch ohne eigene Entwicklung für verschiedenste Geschäftsfälle nutzen lässt: Dokumentenmanagement, Wissenssuche, intelligente Analysen und automatische Zitationen werden per Drag & Drop und KI zugänglich.
9. Hands-On: Praxisbeispiele & Code-Snippets
9.1 Wort- & Satz-Embeddings mit Python & Hugging Face
Dank Open-Source-Frameworks wie Hugging Face ist die Nutzung von Embeddings heute für jeden machbar:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["Künstliche Intelligenz ist spannend.", "Machine Learning begeistert!"]
embeddings = model.encode(sentences)
Damit lassen sich etwa Dokumente, Supportanfragen oder Suchabfragen direkt als Vektoren vergleichen.
9.2 Embeddings für Bilder und Graphen
Für Bilddaten greifen Entwickler beispielsweise auf ResNet, EfficientNet oder CLIP zurück. Hier ein Python-Beispiel für Bild-Embeddings mit PyTorch:
import torch
from torchvision import models, transforms
from PIL import Image
model = models.resnet50(pretrained=True)
model.eval()
model_embedding = torch.nn.Sequential(*list(model.children())[:-1])
img = Image.open('example.jpg')
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_tensor = preprocess(img).unsqueeze(0)
with torch.no_grad():
emb = model_embedding(img_tensor)
9.3 Eigene Embedding Spaces erstellen & visualisieren
Zur Visualisierung bietet sich die t-SNE-Plot-Implementierung in sklearn an:
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(n_components=2, random_state=42)
points_2d = tsne.fit_transform(embeddings)
plt.scatter(points_2d[:,0], points_2d[:,1])
plt.title("Embedding Space Visualisierung")
plt.show()
9.4 Semantische Suche und Ähnlichkeitsmetriken implementieren
Mit wenigen Zeilen lässt sich eine semantische Suche aufbauen – z.B. mit der Kosinus-Ähnlichkeit aus numpy:
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b)/(np.linalg.norm(a)*np.linalg.norm(b))
So findest du das ähnlichste Dokument zu einer Nutzeranfrage direkt über den Embedding-Vergleich.
FAQ – Häufige Fragen rund um Embeddings
- Was ist der Unterschied zwischen Tokenisierung und Embedding?
Die Tokenisierung zerlegt Rohdaten in kleinste Einheiten (Tokens/IDs). Embeddings übersetzen diese IDs in dichte Zahlenvektoren, die semantische (Bedeutungs-)Information transportieren. - Können Embeddings für alle Datentypen genutzt werden?
Ja – von Text, über Bilder, Audio bis Graphen und sogar Multimodal-Anwendungen. Je nach Anwendungsfall gibt es spezialisierte Modelle. - Wie groß sollte die Dimensionalität eines Embeddings sein?
Das hängt von der Aufgabe ab: Für einfache Beziehungen reichen 2-3 Dimensionen, moderne Sprachmodelle nutzen meist 256 bis 2048 Dimensionen. Faustregel: Je komplexer das Problem, desto mehr Dimensionen werden benötigt. - Wie gehe ich mit sehr großen Embedding-Datenmengen um?
Vektordatenbanken, Indextechnologien, Speicheroptimierung (Compression/Quantisierung) und Cloud-Lösungen helfen, auch Millionen Embeddings performant zu nutzen.
Mit diesem Wissen ausgestattet bist du optimal vorbereitet, um Embeddings produktiv zu nutzen – ob in Forschung, KI-Entwicklung oder Unternehmensanwendung.