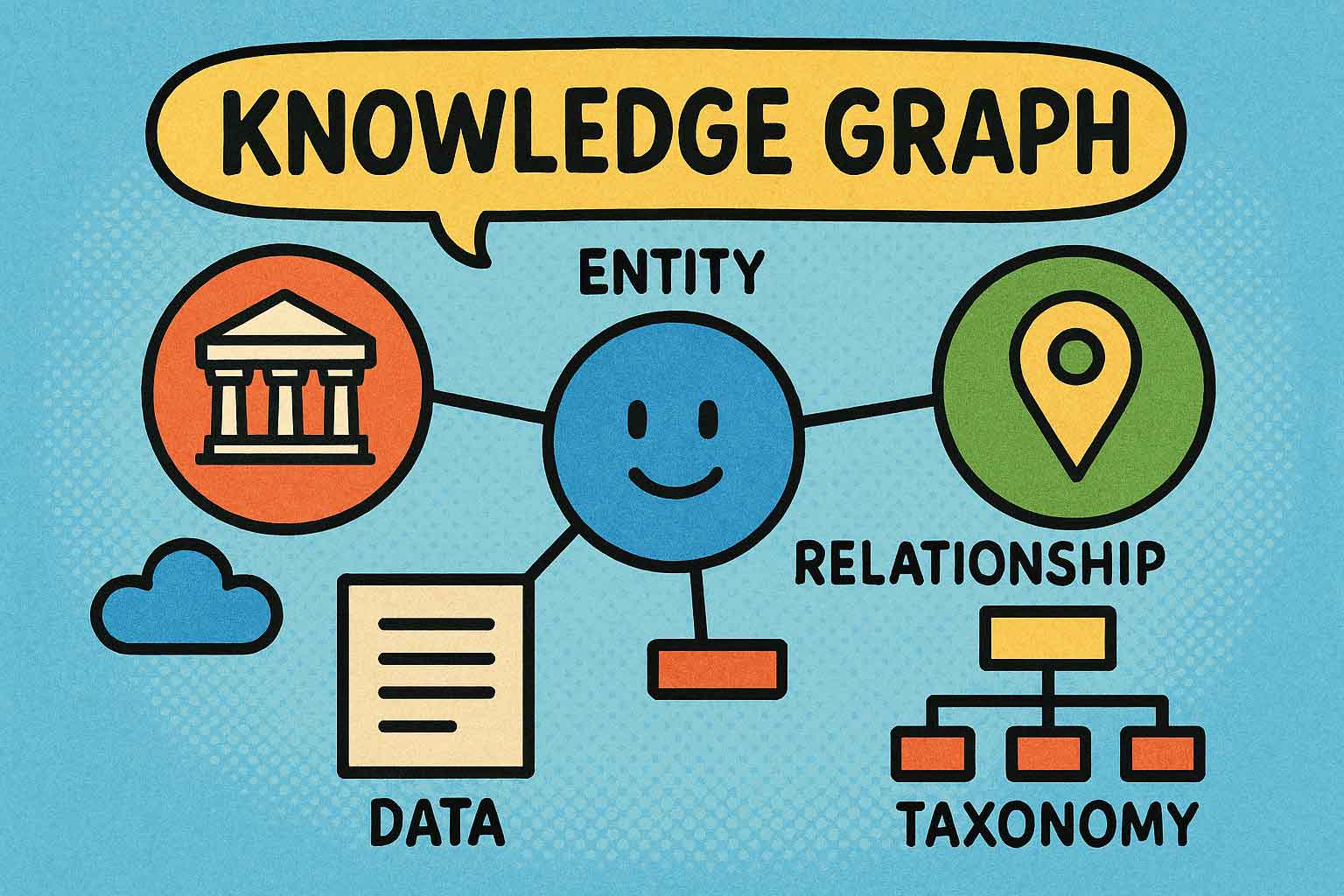
tl;dr - Was ist ein Wissensgraph?
Ein Wissensgraph ist eine smarte Datenstruktur, die Wissen über reale Objekte und deren Beziehungen so verknüpft, dass Maschinen den Kontext und die Bedeutung verstehen können. Statt isolierter Informationen entstehen vernetzte Wissensnetzwerke, die komplexe Fragen beantworten, Zusammenhänge erkennen und KI, Suche oder Empfehlungen deutlich intelligenter machen. Unternehmen nutzen Wissensgraphen, um aus ihren Daten echten Mehrwert zu generieren – von Suchmaschinen bis zu Big Data und künstlicher Intelligenz.
1. Unterschied zu klassischen Wissensbasen und Datenbanken
Das Konzept des Wissensgraphen hebt sich deutlich von traditionellen Wissensbasen und Datenbanksystemen ab. Während Datenbanken strukturierte Informationen punktuell ablegen und meist auf „exakten“ Abfragen mit festen Schemata angewiesen sind, fokussiert sich der Knowledge Graph auf die Bedeutung (Semantik) und die Beziehungen zwischen Datenpunkten. Ebenso unterscheiden sich Knowledge Graphs von einfachen Wissensbasen oder FAQ-Systemen, die meist wenig tiefe Verlinkungen zwischen Wissenseinheiten haben und selten maschinell auswertbar sind.
Das Resultat: Ein Wissensgraph kann komplexe Anfragen beantworten („Nenne mir deutsche Physiker, die im 20. Jahrhundert den Nobelpreis erhalten haben und deren Forschung heute als Grundlage für KI-Anwendungen dient“), transparent die zugrundeliegenden Ursprünge (Zitate, Quellen) darlegen und dabei Kontext, Synonyme oder zeitliche Abläufe bedenken.
2. Grundlagen der Struktur: Aufbau und Komponenten
Knoten, Kanten und Attribute
Die Grundbausteine eines Knowledge Graphs sind Knoten (auch als „Nodes“ oder „Entitäten“ bezeichnet), Kanten (englisch: „Edges“, repräsentieren Beziehungen) und Attribute (Eigenschaften oder Metadaten).
- Knoten: Repräsentieren Objekte oder Konzepte – z. B. eine Person, eine Stadt, ein Forschungsartikel, ein Unternehmen oder ein Ereignis.
- Kanten: Verknüpfen zwei Knoten und drücken die Beziehung aus („arbeitet für“, „ist Teil von“, „wurde geboren in“).
- Attribute: Beschreiben spezifische Eigenschaften eines Knotens („Geburtsdatum“, „Bevölkerungszahl“) oder einer Beziehung („seit wann“, „Stärke der Verbindung“).
Im Gegensatz zu herkömmlichen Tabellen speichern Graphdatenbanken direkt und explizit, wie Knoten miteinander verknüpft sind. Das ermöglicht blitzschnelle Abfragen entlang komplexer Beziehungsnetze.
Beziehungstypen und Organizing Principles
Nicht jede Beziehung ist gleich – Knowledge Graphs nutzen unterschiedliche Typen, um die Vielzahl an realen Verbindungen abzubilden. Beispiele:
- Hierarchische Beziehungen: „ist eine Unterkategorie von“, „ist Teil von“
- Assoziative Beziehungen: „arbeitet mit“, „verwandt mit“, „ähnelt“
- Temporale Beziehungen: „war aktiv in“, „ereignete sich am“
Darüber hinaus geben sogenannte Organizing Principles oder Schemata dem Netzwerk eine übergeordnete Struktur. Sie bestimmen, wie Knoten und Beziehungen organisiert werden – von einfachen Taxonomien (Klassifikationen) bis hin zu komplexen semantischen Netzwerken (z. B. komplette Business-Vokabulare einer Branche).
Von RDF bis Property Graphs: Modellierungsvarianten
Die bekanntesten technologischen Modelle zur Abbildung von Knowledge Graphs sind:
- RDF (Resource Description Framework): Daten werden in Form von Tripeln (Subjekt-Prädikat-Objekt) strukturiert. Beispiel: („Albert Einstein“, „hat Geburtsort“, „Ulm“). RDF ist ein Web-Standard, der insbesondere im Bereich der Linked Open Data und der semantischen Web-Ressourcen breite Anwendung findet.
- Property Graphs: Knoten und Kanten können beliebige Eigenschaften (Properties) besitzen. Moderne Graphdatenbanken wie Neo4j nutzen dieses Modell und bieten hohe Flexibilität sowie beste Performance für komplexe analytische Abfragen.
Beide Ansätze bieten unterschiedliche technische Möglichkeiten, um Beziehungen und Wissen darzustellen. Die Wahl des Modells hängt von den Anforderungen und Anwendungsfällen ab.
3. Ontologien und Semantik: Die Rolle der formalen Wissensorganisation
Ontologien als Schemas für den Knowledge Graph
Im Herzen eines jeden Wissensgraphen liegt eine sogenannte Ontologie. Eine Ontologie fungiert als formales Vokabular bzw. als ein „Schema auf Steroiden“, das genau festlegt, welche Klassen von Entitäten und Beziehungstypen existieren, wie sie untereinander in Beziehung stehen und welche Eigenschaften sie haben können.
Beispiel: Eine Ontologie für das Gesundheitswesen könnte definieren: Patient, Arzt, Diagnose, Krankheit, Medikament – und festlegen, dass ein Arzt eine Diagnose bei einem Patienten stellt und dieser anschließend ein Medikament verschrieben bekommt. Ontologien bilden somit das Gerüst, das sowohl Menschen als auch Maschinen ein gemeinsames Verständnis über die Bedeutung der Daten ermöglicht („shared semantics“).
Semantik und Kontext: Warum Bedeutung entscheidend ist
Was Knowledge Graphs so mächtig macht, ist die Fähigkeit, nicht nur Datensätze zu verknüpfen, sondern „Verstehen“ in den Daten zu verankern. Semantik bedeutet, dass jeder Knoten, jede Beziehung, ja selbst jeder Attributwert im Kontext korrekt interpretiert wird. Finden Sie zum Beispiel „Apple“: Ist damit der Obstklassiker oder das Technologieunternehmen gemeint? Nur durch Kontext und Ontologie erkennt der Graph, dass es sich bei einer Abfrage zur Umsatzentwicklung wohl um das Unternehmen handelt.
Die semantische Vernetzung sorgt nicht nur für Klarheit bei Mehrdeutigkeiten, sondern ermöglicht auch automatische Schlussfolgerungen („Wenn A der Vater von B ist und B der Vater von C, dann ist A der Großvater von C“). Diese Inferenzkraft hebt den Knowledge Graph weit über statische Datenstrukturen hinaus.
4. Erstellung und Pflege von Knowledge Graphs
Datenintegration aus heterogenen Quellen
Das Erstellen eines effektiven Knowledge Graphs beginnt mit der Integration aus einer Vielzahl von Quellen: strukturierte Datenbanken (z. B. CRM-Systeme), semi-strukturierte Dateien (z. B. CSV, XML), unstrukturierte Inhalte (z. B. wissenschaftliche Artikel, E-Mails, Webseiten) oder sogar Echtzeitdaten aus Sensoren und APIs. Entscheidend ist, dass die ursprünglichen Datenformate in ein gemeinsames, semantisch konsistentes Modell transformiert werden.
Moderne Tools nutzen Natural Language Processing (NLP), Entity Recognition und Machine Learning, um automatisch relevante Fakten aus Texten zu extrahieren, Entitäten zu identifizieren und diese in den Graphen einzufügen. Dies reduziert manuellen Aufwand und sorgt für kontinuierliche Aktualität.
Automatisierte und manuelle Methoden der Wissensmodellierung
Die Wissensmodellierung kann über verschiedene Wege erfolgen:
- Manuell durch Experten: Domänenspezialisten entwerfen Ontologien und pflegen relevante Fakten direkt in den Graphen ein (z. B. bei hochregulierten Branchen oder sehr spezifischem Wissen).
- Automatisch via Machine Learning & Text Mining: Algorithmen erkennen Entitäten und Beziehungen in großen Textmengen, extrahieren Wissen und überführen es automatisiert in den Graphen.
- Semi-automatisch durch hybride Workflows: Mensch und Maschine arbeiten gemeinsam – Tools schlagen Fakt- oder Beziehungs-Kandidaten vor, Experten überprüfen und bestätigen.
Gerade bei der Pflege großer, lebender Graphen gilt: Automatisierte Prozesse sichern Effizienz, Experten sichern die Präzision und Korrektheit.
Wartung, Aktualisierung und Qualitätssicherung
Ein Knowledge Graph ist kein statisches Gebilde; er wächst, verändert und verbessert sich mit jeder neuen Information. Dafür müssen Prozesse etabliert werden, um:
- Veraltete oder inkorrekte Fakten zu erkennen und zu entfernen
- Inkonsistenzen oder Dubletten zu bereinigen
- Neue Entitäten, Eigenschaften und Beziehungen einzufügen
- Qualitätsmetriken kontinuierlich zu überwachen (z. B. Vollständigkeit, Aktualität, Trust Score)
Außerdem ist es wichtig, Mechanismen zur Versionierung von Graph-Inhalten und zur Protokollierung von Änderungen (Change-Tracking) zu nutzen. Je nach Anwendungskontext spielen Datenschutz und Zugriffskontrolle eine zunehmend große Rolle – besonders beim Umgang mit sensiblen Personen- oder Unternehmensdaten.
5. Anwendungen und Nutzen in der Praxis
Suchmaschinen, Recommendation Engines und KI-Fragebeantwortung
Eines der bekanntesten Anwendungsbeispiele ist die Google-Suche. Suchen Sie nach „Albert Einstein“, erscheint rechts auf der Seite ein Wissenspanel – bereitgestellt durch den Google Knowledge Graph. Diese Panels liefern gebündelte, relevante Informationen zu Personen, Orten, Organisationen und ermöglichen sogar Vergleiche oder direkte Antworten (Answer Boxes).
Auch Empfehlungsdienste profitieren von dem Konzept: Streamingdienste wie Netflix und Spotify setzen Knowledge Graphs ein, um Inhalte anhand komplexer Zusammenhänge zu empfehlen („Wer dieses Genre mag und Schauspieler A folgt, sollte auch Film B sehen“). In intelligenten Chatbots und Sprachassistenten (Alexa, Siri, Google Assistant) nutzt die KI die semantische Vernetzung, um komplexe Fragen zu verstehen und zu beantworten.
Ebenso findet die Technologie längst im Bereich Dokumentenmanagement und Wissensarbeit Anwendung. Moderne Plattformen ermöglichen es, strukturierte und unstrukturierte Dokumente sicher zu speichern, deren Inhalte intelligent zu analysieren und individuelle Wissensgraphen aufzubauen. So kann etwa die gezielte Volltextsuche ebenso wie die Beantwortung komplexer inhaltlicher Fragen über die eigenen Dokumentensammlungen realisiert werden – inklusive direkter Quellennachweise und fundierter Zusammenfassungen. Lösungen wie Researchico erfassen dazu die Beziehungen zwischen den im Unternehmen oder Team gespeicherten Wissensdokumenten, verknüpfen automatisch die relevanten Informationen und bieten Nutzern eine besonders effiziente, sichere und kontextbezogene Arbeit mit ihren Datenbeständen.
Branchenbeispiele: Gesundheit, Finanzen, Handel, Forschung, Medien
- Gesundheitswesen: Diagnoseunterstützung, Behandlungsvorschläge durch Verknüpfung von Patientenakten, Studien, Wirkstoffdatenbanken und Leitlinien.
- Finanzen: Betrugsdetektion über die Analyse von Transaktionsnetzwerken, KYC zur Identifikation verdächtiger Kunden, Marktanalysen durch graphbasierte Investoren- und Unternehmensnetzwerke.
- Handel & E-Commerce: Verbesserung der Produktsuche, Cross- und Upselling durch genaue Modellierung von Kaufverhalten, Trends und Produktbeziehungen.
- Forschung und Wissenschaft: Wissensentdeckung durch Verknüpfung von Publikationsdaten, Zitaten, Experimentdaten und internationalen Projekten.
- Medien: Visualisierung und Aufdeckung von Zusammenhängen im investigativen Journalismus, z. B. bei der Analyse von Offshore-Geschäften oder internationalen Beziehungen.
Unterstützung moderner KI-Systeme und Explainable AI
Für moderne KI-Anwendungen sind Knowledge Graphs von doppeltem Nutzen: Einerseits dienen sie als zuverlässige Wissensquelle für datenhungrige Algorithmen; andererseits ermöglichen sie die Nachvollziehbarkeit und Erklärbarkeit von KI-Handlungen („Warum hat die KI diese Empfehlung ausgesprochen?“). So wächst das Vertrauen in automatisierte Systeme, während gleichzeitig Innovation gefördert wird.
6. Vergleich & Auswahl von Technologien
Graphdatenbanken vs. relationale Datenbanken
Relationale Datenbanken legen Informationen in fest definierten Tabellen und Zeilen ab. Beziehungen müssen über aufwendige Join-Operationen erzeugt werden. Bei wachsender Daten- und Beziehungskomplexität stoßen sie schnell an technische Grenzen – insbesondere bei Aufgaben wie Echtzeit-Suchvorgängen oder der Entdeckung verborgener Netzwerke.
Graphdatenbanken hingegen speichern die Beziehungen direkt als „First-Class Citizen“. Das heißt: Pfade von „A“ zu „B“ werden nicht neu berechnet, sondern sind bereits als Kanten im Speicher angelegt. Abfragen wie „Wer sind alle direkten und indirekten Geschäftspartner von Unternehmen X?“ lassen sich wesentlich performanter und intuitiver umsetzen.
Property Graphs vs. Triple Stores (RDF)
Zwei führende Paradigmen im Knowledge-Graph-Umfeld sind:
- Triple Stores: Setzen auf das RDF-Modell mit Tripeln aus Subjekt-Prädikat-Objekt. Vorteile: Standardisiert, geeignet für Linked Open Data und Interoperabilität. Nachteile: Weniger performant bei vielen Eigenschaften oder bei Mehrfach-Beziehungen zwischen Knoten; komplexe Modellierungen können zu größeren, schwer wartbaren Datenbanken führen.
- Property Graphs: Bieten Knoten und Kanten, denen beliebig viele Eigenschaften zugewiesen werden können. Vorteil: Hohe Flexibilität, starke Performance, natürliche Abbildbarkeit realer Beziehungsnetze. Beispiel: Neo4j ist die führende Property-Graph-Datenbank.
Die Wahl des Modells hängt stark von Anwendungsfall, Interoperabilitätsanforderungen und technologischem Ökosystem ab.
Auswahlkriterien für Unternehmen und Entwickler
- Komplexität und Umfang des Anwendungsfalls: Kleine, schlanke Lösungen können mit einfachen Property Graphs starten, komplexe Datenlandschaften mit mehreren externen Quellen profitieren von RDF.
- Interoperabilität und Integration: Bedarf es des Austauschs mit internationalen, offenen Datenquellen? RDF ist dafür prädestiniert. Für unternehmensinterne Lösungen bieten Property Graphs oft mehr Agilität.
- Performance: Echtzeit-Analysen und viele Verknüpfungen? Property Graphs sind meist überlegen.
- Entwicklerökosystem, Tools und Support: Wie gut ist der Zugang zu Werkzeugen, Libraries und Community?
7. Aktuelle Herausforderungen und Trends
Skalierbarkeit, Datenqualität und Sicherheit
Mit dem Wachstum der Graphen steigen die Herausforderungen:
- Skalierbarkeit: Moderne Knowledge Graphs umfassen Milliarden von Fakten und Beziehungen; effiziente Speicher- und Abfragearchitekturen sind Pflicht.
- Datenqualität: Fehlerhafte, veraltete oder unvollständige Informationen können schnell zu ungenauen Ergebnissen oder fehlerhaften Schlussfolgerungen führen.
- Sicherheit & Datenschutz: Gerade bei sensiblen Anwendungsfällen müssen rollenbasierte Zugriffskontrollen, Verschlüsselung und DSGVO-/HIPAA-Konformität beachtet werden.
Zusammenspiel mit Machine Learning und NLP
Das Potential eines Knowledge Graphs wird erst durch die Verbindung mit datengetriebenen Ansätzen voll ausgeschöpft. Moderne Pipelines nutzen:
- Natural Language Processing (NLP): Automatisches Extrahieren von Entitäten und Beziehungen aus Textquellen.
- Machine Learning: Ergänzung um Inferenz, Wissenslücken schließen, Unsicherheiten erkennen (Confidence Scores), Anomalien entdecken.
- Semantische Anreicherung: Fakten aus Texten und Bilddaten werden dem Graphen hinzugefügt und vernetzt.
Innovative KI-Architekturen kombinieren symbolische Repräsentation (Graphen) mit neuronalen Netzen, um Transfer-Learning zu ermöglichen und Explainable AI zu stärken.
Neue Formen von Knowledge Graphs: Common Sense, Event Graphs, etc.
Die Zukunft geht weit über die reine Modellierung von „Fakten“ hinaus. Moderne Forschungsprojekte widmen sich etwa folgenden Themen:
- Alltagswissen & Common Sense: Integration von Menschenverstand, Plausibilität und sozialem Kontext.
- Event Graphs: Modellierung von Ereignissen, deren Abfolge und Kausalzusammenhängen – z. B. für Zeitreihenanalysen und Prognosen.
- Multiple Perspektiven & Unsicherheiten: Repräsentation unterschiedlicher Wahrheiten oder Autorenstandpunkte im Graphen für eine umfassende Sicht.
Mit diesen Entwicklungen werden Knowledge Graphs immer flexibler, anpassungsfähiger und wertvoller für KI-Anwendungen der nächsten Generation.
8. Bekannte Beispiele und offene Knowledge Graphs
Es gibt weltweit eine Reihe von frei nutzbaren sowie proprietären Knowledge Graphs, die als Leuchttürme und Integrationsplattformen für Forschung, KI-Entwicklung und Industrieanwendungen dienen:
- Google Knowledge Graph: Herzstück der Google-Suche, mit hunderten Millionen Entitäten (Menschen, Orte, Organisationen) und Milliarden Datenpunkten. Großteils proprietär und kaum extern nutzbar.
- Wikidata: Freies, gemeinschaftlich kuratiertes Wissensdatenbankprojekt, das eine strukturierte, maschinenlesbare Oberfläche zu den Inhalten von Wikipedia und anderen Wikimedia-Projekten bietet.
- DBpedia: Extrahiert strukturierte Daten aus den Infoboxen von Wikipedia-Artikeln und vernetzt sie als Linked Open Data.
- Wordnet: Lexikalische Datenbank für das Englische, mit Synonym- und Bedeutungsclustern – häufig eingesetzt für NLP und Sprachverarbeitung.
- Geonames: Umfassende geografische Datenbank mit Millionen von Orten und topografischen Eigenschaften.
Viele Unternehmen entwickeln zudem unternehmensinterne, domänenspezifische Knowledge Graphs (z. B. FactForge für Finanz- und Newsdaten, Amazon Produktempfehlungsgraph), die Wettbewerbsvorteile schaffen, aber selten öffentlich zugänglich sind.
9. Zukunftsausblick: Knowledge Graphs als Schlüsseltechnologie der vernetzten Welt
Knowledge Graphs stehen an der Schwelle, einen neuen Standard für den Umgang mit Wissen, Daten und Informationen in der digitalen Ära zu setzen. In einer Zeit, in der Datenmengen exponential anwachsen und Wissen immer stärker verteilt ist, bieten sie einen systematischen Weg, den Informations-Overload zu bewältigen, Zusammenhänge zu erkennen und Innovation zu beschleunigen.
Sie werden zum Bindeglied für die Human-AI-Kollaboration: Komplexe Entscheidungen, datengetriebenes Arbeiten und erklärbare KI sind ohne intelligente Vernetzung kaum noch denkbar. Unternehmen, die frühzeitig auf Knowledge Graphs setzen, werden nicht nur schneller Wissensvorsprünge erzielen, sondern auch flexibler auf Veränderungen reagieren, regulatorische Anforderungen besser erfüllen und neue Geschäftsfelder erschließen können.
Auch in Wissenschaft, Digitalpolitik und der Zivilgesellschaft werden Knowledge Graphs dazu beitragen, Wissen transparenter, zugänglicher und kollaborativer zu machen – sei es bei der Bekämpfung von Fake News, in Open Education oder im Umweltschutz.
10. Fazit: Warum Knowledge Graphs für Unternehmen und KI unerlässlich werden
Wer heute klug Daten vernetzen und aus riesigen Informationsmengen echtes Wissen schöpfen möchte, kommt an Knowledge Graphs nicht mehr vorbei. Sie bilden das Rückgrat intelligenter Such- und Empfehlungssysteme, ermöglichen dynamische, kontextbewusste Prozesse in Unternehmen und schaffen die Basis für erklärbare und vertrauenswürdige KI-Anwendungen.
Die Revolution der Wissensarbeit hat gerade erst begonnen. Unternehmen, Forschungseinrichtungen und Entwickler, die die Kraft von Knowledge Graphs nutzen, werden die Champions der datengetriebenen Zukunft sein.