tl;dr – What are Embeddings?
Embeddings for AI and Machine Learning are the key technology for transforming complex data such as texts, images, and graphs into numerical vectors. This enables artificial intelligence and machine learning models to efficiently recognize, compare, and utilize relationships, meanings, and patterns. In this guide, you will learn how embeddings work, what types exist, how they are used in everyday AI applications, and how you can use them in your own projects – from NLP to recommendation systems to image analysis and modern search engines.
1. What are Embeddings? – Basics and Significance
In the rapidly advancing world of artificial intelligence (AI) and machine learning (ML), one term keeps appearing: Embedding. Often operating in the background, embeddings form the invisible bridge between the rich, chaotic reality of text, images, and other data sources – and the machine processing that distills actionable knowledge from it. This blog post is different from the usual, often dry definitions: We’ll take you on a journey from the very first basics, through fascinating deep dives, all the way to practical tips and code examples. You’ll learn how embeddings work, what revolutionary possibilities they offer – and how you can use them yourself to extract real value from your data.
1.1 Definition: What are Embeddings?
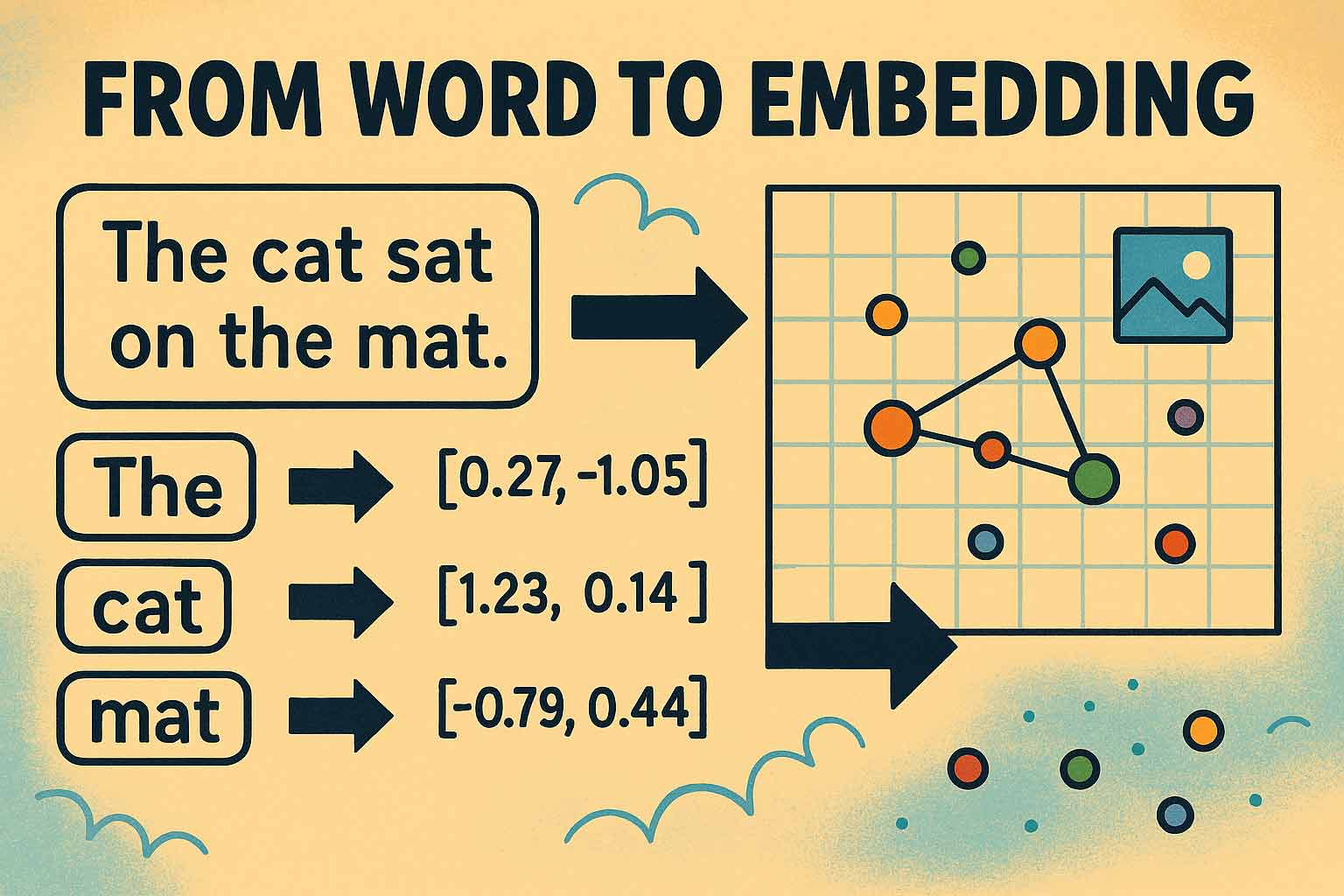
Imagine if you could translate the meaning of words, images, or even music into a precise mathematical form – so that computers could instantly recognize connections, similarities, and differences. That’s exactly what embeddings do: They transform complex objects like words, sentences, documents, images, or even network structures into so-called vectors – lists of numbers of various lengths that can be arranged in a so-called vector space.
These vector representations enable machines to “understand” the semantic proximity between objects. For example, two similarly intended texts will be assigned similar sequences of numbers – their points in space lie close to each other. This leads to impressive applications: from lightning-fast searches for similar documents to personalized recommendations, and intelligent fraud detection in financial data.
1.2 Why are Embeddings Essential for AI?
The human mind intuitively recognizes similarities and relationships – whether between concepts, images, or abstract ideas. Computers, however, need numeric representations to identify patterns. Without embeddings, machines would have to explicitly compare all possible variants and combinations – an unsolvable problem given the sheer amount of data.
Embeddings compress relevant content intelligently while preserving the most important information: meaning, context, relationships. They form the backbone of modern AI applications such as search engines, recommendation systems, chatbots, and language models like GPT or BERT.
1.3 Historical Development & Overview
The idea of encoding content numerically as vectors has existed since the earliest days of information retrieval. In the past ten years, however, the technology has evolved rapidly: from simple one-hot encodings and static dictionaries like Word2Vec, to complex, context-dependent models – above all BERT and modern Transformer approaches.
- Early approaches: Simple relationship models, e.g. bag-of-words vectors.
- Static embeddings: Word2Vec, GloVe – the first to bring semantic proximity into the number space.
- Contextual embeddings: BERT & co. can translate the same words differently depending on context.
Today, embeddings are among the key technologies in any advanced AI – be it for text, image, audio, or complex networked data.
2. From Raw Data to Vector Space: How are Embeddings Created?
2.1 The Role of Tokenization
2.1.1 What is Tokenization – and How Does It Differ from Embeddings?
Before an AI system can generate embeddings at all, raw data needs to be preprocessed. Especially for text data, the so-called tokenization is used: it breaks continuous text into smaller units – called tokens. These can be words, syllables (subwords), or characters.
The task of tokenization is to break text into components in such a way that the computer can work with them – it turns language into a sequence of symbols or IDs. Only with these IDs can a subsequent embedding model process and generate a vector (list of numbers) for each token.
2.1.2 Examples: Tokenization vs. Embedding
- Tokenization: “I love machine learning” → [“I”, “love”, “machine”, “learning”] → [101, 2293, 724, 1331]
- Embedding: The numbers (“token IDs”) are translated into fixed vectors: [0.12, -0.54, ...]
- Key difference: Tokenization arranges and encodes – embeddings add meaning and context!
2.2 From Token to Vector: The Embedding Process
2.2.1 Numerical Representation of Objects (Low-Dimensional/Dense Vectors)
After tokenization, the individual tokens are translated into numerical vectors by the embedding model. Imagine this process like a map: Each object (e.g. a word) gets coordinates in a space that often has hundreds or thousands of dimensions. The position of the points reflects semantic similarity – “car”, “vehicle”, and “truck” are placed closely together, while “pizza” and “book” are farther apart.
This transformation tames the original, high complexity of the data and makes it understandable for the algorithm. Instead of dealing with millions of individual combinations, it's enough to look at the position and distance of points in vector space to automatically identify relationships.
2.2.2 Dimensions and Their Meaning
The so-called dimensionality of an embedding determines how many properties can be represented simultaneously. In practice, two or three dimensions are sufficient for simple examples (e.g. place on a map), while word embeddings or image features often have vectors with 256, 512, 768, or even 2048 dimensions.
The fascinating thing is: the more dimensions, the more finely complex relationships can be stored – even though most dimensions are no longer intuitively accessible to the human eye.
2.3 Architecture of Modern Embedding Models
2.3.1 Neural Networks: Embedding Layer, Training Process & Backpropagation
Modern embeddings are usually learned using deep neural networks (“deep learning”): At their core, many networks contain a specific embedding layer that maps token IDs to vectors. During training, these layers automatically refine relevant dimensions of meaning.
- The training process is usually supervised (e.g. for prediction tasks) or self-supervised, as in masked language modeling.
- Backpropagation algorithms continuously optimize embedding vectors: Similar objects are brought closer together based on feedback from training.
The embedding vectors thus generated are stored in the model after training and are ready for queries or further tasks.
2.3.2 Lossy Compression: Opportunities and Limitations
A central principle with embeddings is lossy compression: To squeeze complex data into lower vector dimensions, some information is inevitably left out. However, the goal is to retain just those semantic features that are most important for the target task.
- Example text: Different shades of meaning or associations might be merged and thus simplified. This often makes models more robust but can result in loss of context.
- Example image: Detail information such as fine gradations of color may be lost, but main objects and their arrangement are preserved.
3. Types of Embeddings and Their Technologies
3.1 Static Embeddings: Word2Vec, GloVe & Co.
3.1.1 Functionality & Advantages
The first major breakthroughs with embeddings came with static methods: Word2Vec (Google), GloVe (Stanford), or FastText (Facebook) translate each word into a fixed vector – independent of the context in which it appears.
The training occurs on massive text corpora. The models learn to group words with similar contexts together in vector space: “King – man + woman = queen” is a classic example of how even analogy operations can be performed directly on embeddings.
3.1.2 Limitations of Static Embeddings (Polysemy etc.)
The downside: A word like “bank” always receives the same vector, whether one is talking about a financial bank or an embankment. Linguistic ambiguities (polysemy) and changes in context are not reflected here.
3.2 Contextual Embeddings: BERT & Transformer-based Approaches
3.2.1 Context-dependency and Semantic Similarity
The introduction of BERT (Google) and related Transformer models marked a paradigm shift: every word, phrase, and sentence receives embedding vectors that are adapted to the situation – depending on the surrounding context.
For example: The word "Java" receives completely different vectors depending on whether it refers to programming, the island, or a cup of coffee. Semantic and syntactic differences are now taken into account by machines for the first time.
The complexity of language and context thus gets much better captured. Also, sentence and document embedding models (e.g. Universal Sentence Encoder or SentenceTransformers) deliver meaningful vectors for entire passages.
3.3 Specialized Embedding Techniques
3.3.1 Image and Audio Embeddings (CNNs, RNNs, CLIP)
In addition to text, embeddings are now applied to a variety of data types:
- Image embeddings: Convolutional Neural Networks (CNNs), such as ResNet, extract image features (feature vectors) that, for example, describe object classes or image similarity. Models like CLIP link image and text properties in a common vector space.
- Audio embeddings: RNNs and CNNs capture acoustic features such as pitch, rhythm, speaker preferences, or even music style as vectors.
3.3.2 Graph Embeddings (Node2Vec, GraphSAGE & Applications)
Embeddings can also be generated for data with relationships – e.g., social networks, molecular structures, or transportation networks. Algorithms like Node2Vec or GraphSAGE transform nodes and edges into connected vectors, capturing meaning and relationships in the network mathematically.
This is especially important for tasks like link prediction (who might connect with whom?), community detection, fraud detection, or recommendation systems.
3.3.3 Multimodal Embeddings: Learning Text, Image & Audio Together
The latest state of the art features multimodal embeddings that holistically represent different data types: For example, the CLIP model links images and the corresponding text into a shared vector format. This enables image searches using descriptive text – or a video can automatically be linked with matching music.
4. Embedding Models in Use: Practical Applications
4.1 Natural Language Processing (NLP) & Search Engines
4.1.1 Semantic Search & Context-based Queries
Embeddings are the core of modern semantic search engines. Instead of matching search terms literally, both the query and the documents themselves are represented as vectors. The computer can then understand that a query for “climate-friendly vacation in the mountains” should also return results like “sustainable travel offers in the Alpine region,” including synonyms or paraphrased sentences.
This revolutionizes, for example, workflows in Researchico, where users can intelligently search their document library and receive comprehensive analyses in natural language using semantic embeddings. This form of semantic search elevates classic keyword-based methods to a new level and is increasingly becoming the standard in digital knowledge management.
4.1.2 Sentiment Analysis, Text Classification, Question-Answering Systems
Embeddings are also indispensable for machine classification of sentiments (“positive/negative”), routing support requests, or in chatbots. Thanks to vector representation, the machine understands nuances of meaning – and is able to form thematic clusters, answer questions precisely, or automatically categorize texts.
4.2 Computer Vision & Image Retrieval
4.2.1 Object Recognition, Classification & Similarity Search
In the field of image analysis, embeddings enable not only rapid and reliable object recognition, but also the search for similar images (e.g. in e-commerce, art, or medical diagnostics). An image is transformed into a feature vector – and this can be compared with millions of others.
4.3 Recommender Systems & Collaborative Filtering
4.3.1 User & Item Embeddings in Recommendation Algorithms
Recommendation engines like those from Netflix or Spotify use embeddings to capture both user and product preferences. The AI learns: “Who likes crime novels will probably enjoy thrillers,” or: “Customers who bought product X also like Y.” Embeddings efficiently combine complex user behavior and content features – the basis for personalized suggestions.
4.4 Graph-based Applications & Network Analysis
Whether in social networks, transportation planning, or molecular and structural analysis: graph embeddings are the key technology for mathematically capturing relationships and structures. From fraud detection to community detection – network views can be analyzed as “clusters in vector space.”
4.5 Anomaly & Fraud Detection
When comparing transaction data, network traffic, or user behavior, embeddings help to discover “outliers” in the dense number space – enabling fraud, hacking patterns, or unusual occurrences to be identified faster than ever before.
4.6 Multimodal and Cross-domain Applications (e.g., CLIP, MUSE)
Evolving data landscapes and the increasing integration of various sources require flexible, multimodal embeddings: These create connections between text, images, or even speech/sound – for example, for accessibility (image recognition with text output), cross-modal search engines, or multilingual translation services.
5. Vector Space Analysis and Similarity Search
5.1 Distance Measures and Similarity Metrics (e.g., Cosine, Euclidean)
Once objects are represented as vectors, the question arises: How to effectively measure their similarity? Most common are:
- Cosine similarity: Measures the angle between two vectors – ideal for text.
- Euclidean distance: Direct distance in n-dimensional space – common for images.
- Other measures: Manhattan, Jaccard, Hamming, and application-specific variants.
The choice of metric directly influences how relevant the results of a search are!
5.2 Visualization of Embeddings (e.g., t-SNE, PCA, UMAP)
To make high-dimensional embedding vectors tangible for humans, methods such as PCA (Principal Component Analysis), t-SNE, or UMAP are used. They project the information down to two or three dimensions, so clusters and proximity relationships become visible – for example, as interactive plot visualizations.
5.3 Vector Databases: Storage and Rapid Search
5.3.1 Structure & Functionality of Vector Databases
As embeddings become increasingly important, so does the need for specialized databases capable of storing, searching, and efficiently matching vectors: so-called vector databases. Core principle: When documents, images, or audio are added, they are automatically converted to embeddings, associated with meta data, and used as a search basis.
- Collections accept any data type
- Search queries are converted into embeddings and compared with the database
- Sorting by similarity (“top-N”) replaces traditional exact keyword search
5.3.2 Examples & Best Practices
Practical applications can be found in intelligent document archives, analysis of large scientific text collections, or rapid (and data-efficient!) image comparison in AI-powered CMS systems.
6. Training Process and Optimization of Embeddings
6.1 Overview: Generating Embeddings with Neural Networks
A central element of any modern embedding structure is the embedding layer in the neural network. It usually starts with random values, which are systematically adjusted during training via feedback (backpropagation).
- With masked language modeling (as in BERT), random words are removed from sentences and the model predicts them – thus learning to optimally capture relationships statistically.
- Through millions to billions of training rounds, dense, meaningful vectors for a wide variety of applications are created.
6.2 Training Data: Importance of Quality & Diversity
No model is better than its training data – especially true for embeddings! Diversity, but also quality (spelling, representativeness, balance of domains) determines how robust and comprehensive the learned relationships are. Pre-trained models can also be fine-tuned specifically (fine-tuning), e.g., for industry-specific language.
6.3 Fine-tuning & Transfer Learning: Domain-specific Adaptation
It’s often worthwhile to adapt a large, pre-trained embedding model to a specific task, such as legal language or medical terminology. So-called fine-tuning uses a small amount of high-quality specialized data to shift the embedding space precisely. Transfer learning is thus extremely data- and time-efficient.
6.4 Monitoring & Evaluation of Embedding Quality
To ensure quality, various methods are used:
- Comparing cosine similarity of known word pairs
- Performance on downstream tasks (e.g., text classification, recommendation)
- Interpretability via visualization (see section 5.2)
Metrics include loss, accuracy, or analogy test tasks.
7. Challenges, Limitations & Best Practices
7.1 Loss of Context Information & Bias
No matter how powerful embeddings are – they’re not without pitfalls! Every compression leads to loss of information. If the training data is poorly chosen, significant biases (e.g., cultural or gender-based distortions) can arise. Also, minor differences in data quality can have major effects on the embedding space.
7.2 Interpretability and the Black Box Problem
The more complex an embedding model is, the harder it is to interpret its results: What does a particular dimension in the vector mean? How can we understand why a model finds two words similar? Both research and practice are consistently working to bring more transparency (“explainable AI”) to these processes.
7.3 Handling Out-of-Vocabulary and Rare Terms
Another problem: Unknown or rare terms (OOV terms) can’t be processed by classic embeddings. Modern models therefore use subword tokenization and byte pair encoding to compose even previously unseen words from known parts.
7.4 Storage Requirements & Efficiency with Large Embedding Spaces
Especially with very large datasets, embedding databases can produce enormous storage and computing requirements. Here, dimension reduction, memory compression (e.g., quantization), and distributed infrastructures help make vector search practical.
8. Outlook and Trends – The Future of Embeddings
8.1 Multimodal & Universal Embeddings
The future is multimodal: Embeddings will represent a wide variety of data sources as well as different languages and cultures in common vector spaces. Universal embeddings will become the key for global, cross-domain AI applications.
8.2 Prompt Engineering vs. Fine-Tuning: Which Approach for What?
Instead of fine-tuning ever larger models, many AI projects now rely on intelligent prompt engineering: Through precise task descriptions and context in the input, even a general language model can be controlled to deliver specific answers. Fine-tuning remains indispensable for highly domain-specific tasks; both approaches complement each other perfectly.
8.3 Integration into Modern AI Workflows and SaaS Solutions (e.g., Researchico)
New SaaS platforms like Researchico demonstrate how powerful embedding technology can be used for various business cases without in-house development: Document management, knowledge search, intelligent analyses, and automatic citation become accessible via drag & drop and AI.
9. Hands-On: Practical Examples & Code Snippets
9.1 Word & Sentence Embeddings with Python & Hugging Face
Thanks to open-source frameworks such as Hugging Face, anyone can now use embeddings:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["Artificial intelligence is exciting.", "Machine learning fascinates!"]
embeddings = model.encode(sentences)
This lets you compare documents, support requests, or search queries directly as vectors.
9.2 Embeddings for Images and Graphs
For image data, developers use, for example, ResNet, EfficientNet, or CLIP. Here’s a Python example for image embeddings with PyTorch:
import torch
from torchvision import models, transforms
from PIL import Image
model = models.resnet50(pretrained=True)
model.eval()
model_embedding = torch.nn.Sequential(*list(model.children())[:-1])
img = Image.open('example.jpg')
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_tensor = preprocess(img).unsqueeze(0)
with torch.no_grad():
emb = model_embedding(img_tensor)
9.3 Creating & Visualizing Your Own Embedding Spaces
For visualization, sklearn’s t-SNE plot implementation is a great choice:
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(n_components=2, random_state=42)
points_2d = tsne.fit_transform(embeddings)
plt.scatter(points_2d[:,0], points_2d[:,1])
plt.title("Embedding Space Visualization")
plt.show()
9.4 Implementing Semantic Search and Similarity Metrics
You can set up a semantic search in a few lines – e.g. using numpy’s cosine similarity:
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b)/(np.linalg.norm(a)*np.linalg.norm(b))
This way, you can directly find the most similar document to a user query via embedding comparison.
FAQ – Frequently Asked Questions about Embeddings
- What is the difference between tokenization and embedding?
Tokenization breaks raw data into the smallest units (tokens/IDs). Embeddings translate these IDs into dense numeric vectors that transport semantic (meaningful) information. - Can embeddings be used for all data types?
Yes – for text, images, audio, graphs, and even multimodal applications. There are specialized models for each use case. - How large should the dimensionality of an embedding be?
This depends on the task: 2-3 dimensions are enough for simple relationships, modern language models typically use 256 to 2048 dimensions. Rule of thumb: The more complex the problem, the more dimensions are needed. - How do I deal with very large amounts of embedding data?
Vector databases, indexing technologies, storage optimization (compression/quantization), and cloud solutions help you efficiently manage even millions of embeddings.
Equipped with this knowledge, you are optimally prepared to use embeddings productively – whether in research, AI development, or in business applications.